
Environment Engineering: The Evolving Role of the Software Engineer

An agent that needs your input every few minutes is a tool. An agent that works autonomously for hours is a colleague. The difference isn’t the agent’s intelligence — it’s the environment you put it in.
Most engineers are focused on what to say to agents — better prompts, better context, better instructions. That matters. But it’s the smaller lever. The bigger lever is what the agent can do: what tools it has, what feedback it gets, how completely it can close its own loop. I call this environment engineering, and it’s becoming the highest-leverage skill in the industry.
Agents Are Capable. They’re Also Trapped.
Coding agents have read more documentation than you ever will. They can assess whether something is working and they know what “done” looks like. These capabilities are already strong, and they’re improving fast — every model generation brings broader knowledge and sharper judgment.
But none of that matters if they can’t reach the real world. Your docs live in Notion. Your UI lives in a browser. Your data lives in a production database. Your requirements live in a Slack thread. The agent can’t grab any of it. It’s a brilliant worker locked in an empty room.
Context Engineering Is Necessary but Insufficient
Context engineering — giving agents the right information to reason well — has gotten a lot of attention. But context lets an agent think about the world. It doesn’t let it act, observe the outcome, and course-correct.
Context only:
Context ──→ Agent reasons ──→ Outputs code ──→ Human tests
↑ │
└─────────── Human provides feedback ───────────┘
The human IS the feedback loop.
Agent stops and waits every cycle.
Environment engineering goes further. An environment is context plus tools and feedback:
Context — the information the agent needs. Instructions, codebase knowledge, documentation, requirements. This is what context engineering already covers.
Tools + Feedback — the actions the agent can take and the signal it gets back. Running tests and seeing pass/fail. Opening a browser and visually inspecting the result. Querying a database and checking the output. Tools without feedback are just buttons the agent pushes blindly. Tools with feedback are how the agent learns whether what it did was right.
Not all tools are equal. A test suite that runs in two seconds and returns a clear failure message is a different instrument than one that takes ten minutes and dumps a wall of stack traces. The engineering skill isn’t just giving agents tools — it’s designing tools that produce fast, precise signal the agent can iterate against. The quality of that signal determines whether the agent self-corrects or spirals.
The Closed Loop Changes Everything
When an agent has context and tools that return strong signal, it can close its own feedback loop:
With a well-designed environment:
┌──── no ─────────────────────────────┐
↓ │
Agent writes code ──→ Runs tests ──→ Pass? ─┘
Opens browser │
Checks types yes
│
↓
Done
No human in the loop.
Feedback steers the agent autonomously.
This is the core unlock. The agent’s autonomous time — how long it can work without needing you — expands from minutes to hours. That expansion is the leverage.
METR’s research puts hard numbers on this. They measure the length of tasks that frontier AI agents can complete autonomously, and found that this time horizon has been doubling roughly every seven months.
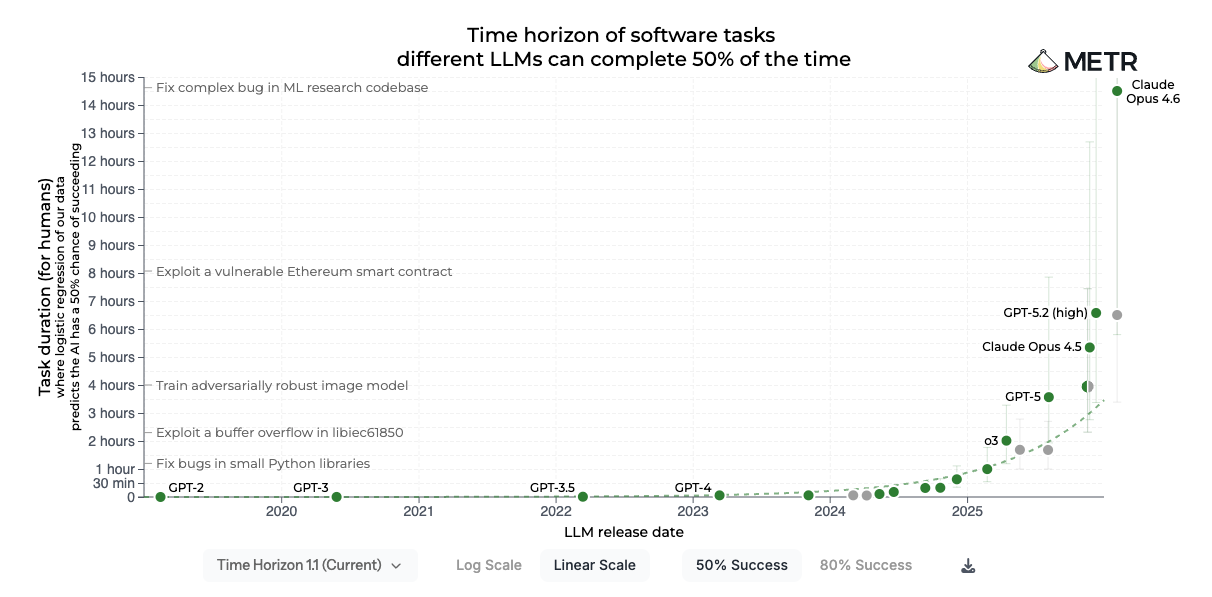
But METR measures the ceiling — what an agent can do under idealized conditions. Whether it actually reaches that ceiling depends on the completeness and quality of the environment. A frontier model in a weak environment — no tests, no browser, no feedback — will underperform a weaker model in a well-designed one. The raw capability is there. The environment is what unleashes it.
The agent is only as good as the signal it iterates against. And once you have a closed loop that works, you can multiply it — run multiple agents in parallel, each in its own isolated environment, each closing its own loop independently. You’re not multiplying your time. You’re multiplying autonomous agents.
What This Looks Like in Practice
I set up isolated Docker containers for frontend development — each with its own database, server, and full application stack — and gave the agent a browser tool so it could open the site, visually inspect the result, and click through the UI.
The feedback design is what makes it work. The agent runs the type checker, executes the test suite, opens the browser, and visually verifies the result. Each tool returns a different signal: types catch structural errors, tests catch logic errors, the browser catches everything a user would actually see. Fast, layered feedback the agent can iterate against.
Before this environment, the loop ran through me. The agent would write code, I’d check the browser, describe what was broken, and the agent would try again. Every iteration cost me five minutes of context-switching, and the agent couldn’t do anything in the meantime.
Now the agent handles the full cycle on its own. It writes code, spins up the stack, opens the browser, sees that a button is overlapping the nav bar, fixes the CSS, re-checks — three iterations I never see. Multiple agents run in parallel across different features without stepping on each other.
This wasn’t a better prompt or a smarter model. It was an investment in the environment.
The Takeaway
The product we build as software engineers is changing. It used to be the software. Now it’s the environment that builds the software — and the quality of that environment directly determines how much of an agent’s raw capability you actually capture.
The engineers who figure this out first — who stop optimizing prompts and start designing environments — will have a compounding advantage as agents improve. Every improvement to the environment pays dividends across every task that runs inside it. Every leap in model capability makes a well-designed environment more powerful.
The agents are getting smarter. The question is whether your environment is ready for them.